

We all know that AI is booming at the minute, and that has had a huge knock-on effect for the PC industry. First the discrete GPUs market was hit, and – more recently – DRAM prices have been rocketing skywards. You may not initially think that a NAND flash manufacturer would have the solution, but Phison's aiDAPTIV+ technology could help shift the AI burden away from memory constraints.
At CES 2026, we stopped to visit Phison and hear about how the company's aiDAPTIV+ tech – what it is, and how it works. While initially announced last year, it's not something we've covered before, so we wanted to share the low-down given the technology makes a good deal of sense.
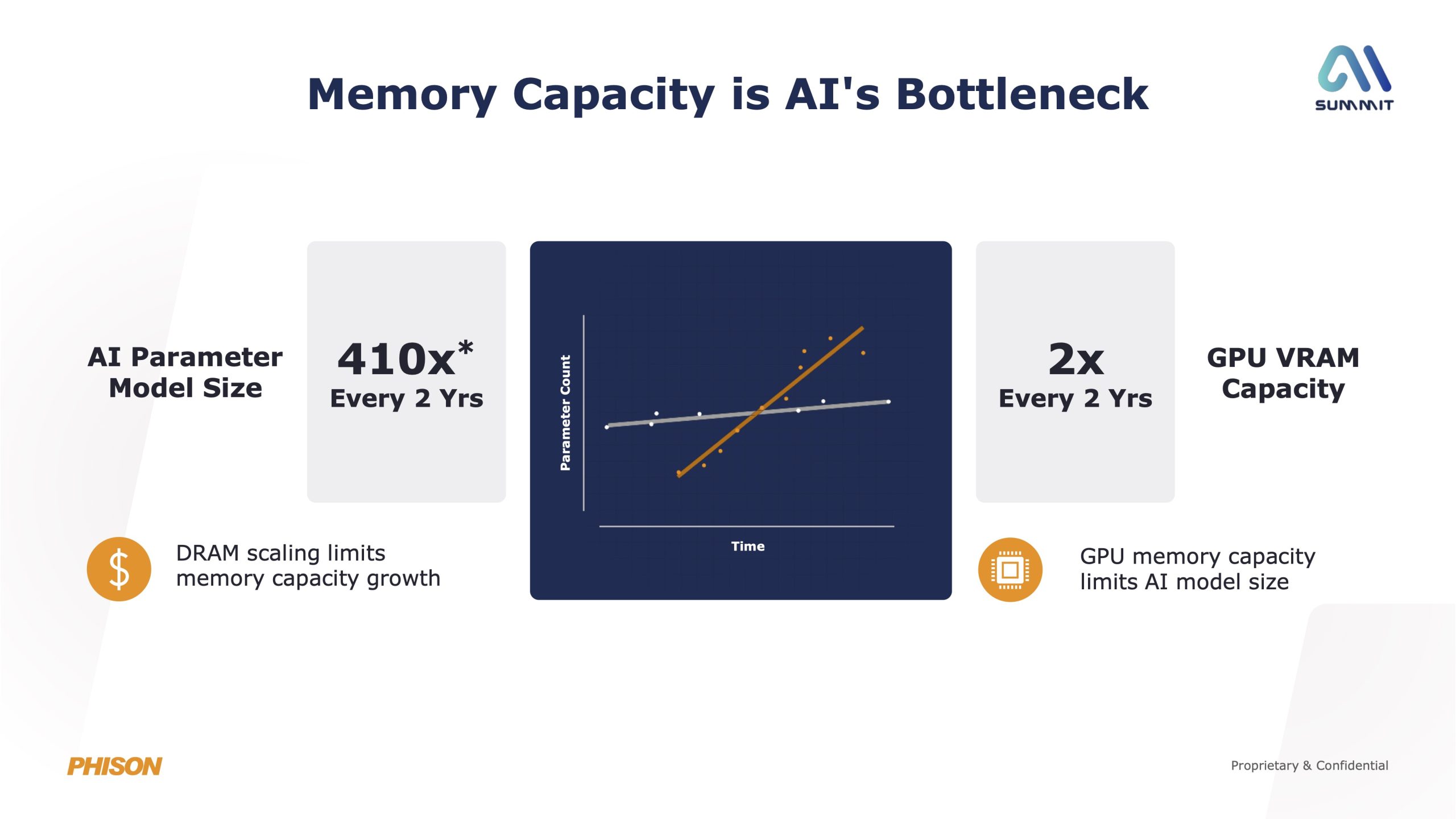
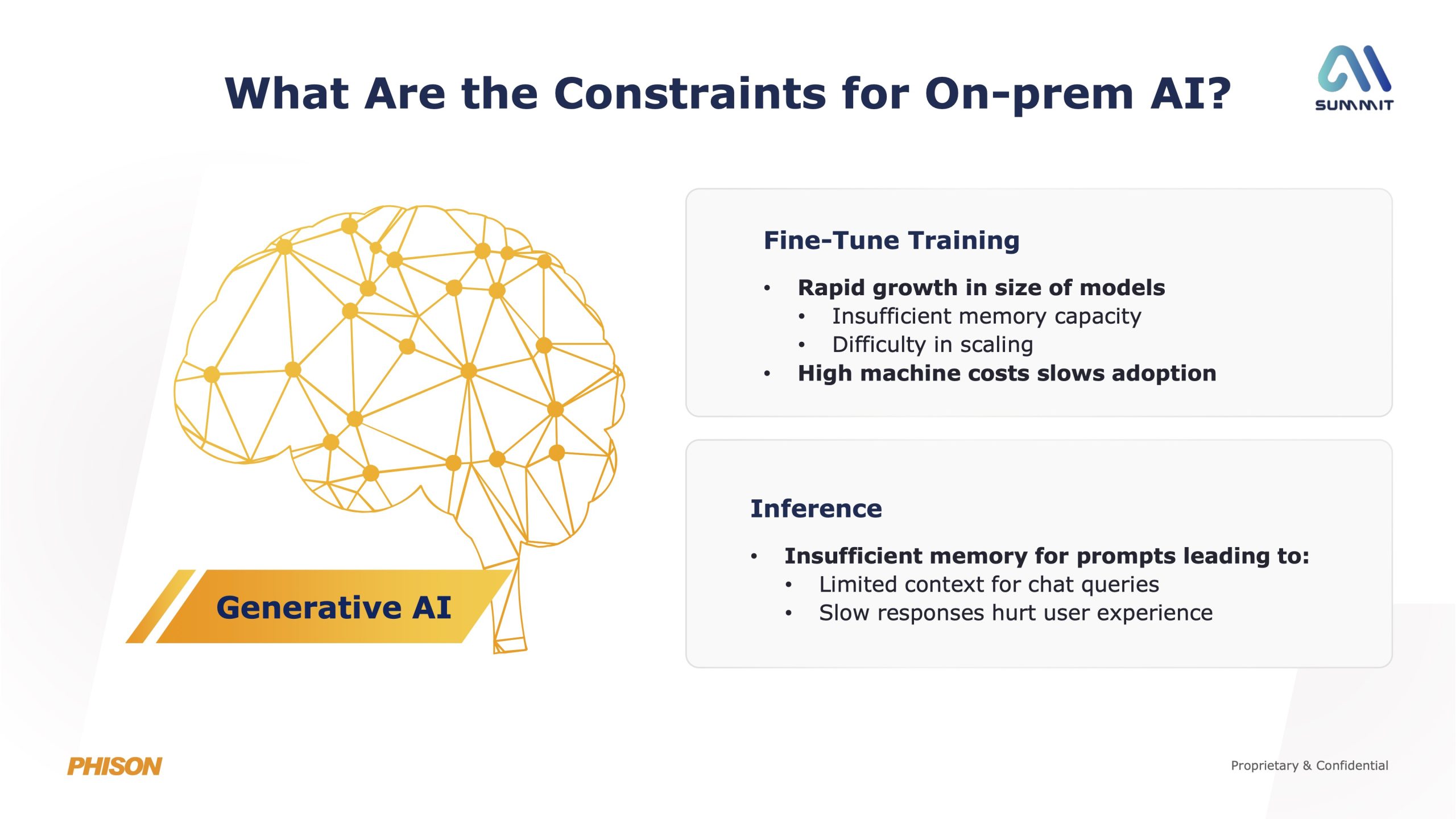
In a nutshell, Phison's aiDAPTIV+ technology is designed to mitigate one key problem area for current AI workflows – limited GPU memory. The company points out that AI models are growing far faster than what VRAM or system DRAM can keep up with, so memory capacity, rather than raw compute, has become the primary bottleneck for local AI training and inference. That, in turn, has implications for both AI model size and performance on your typical PC.
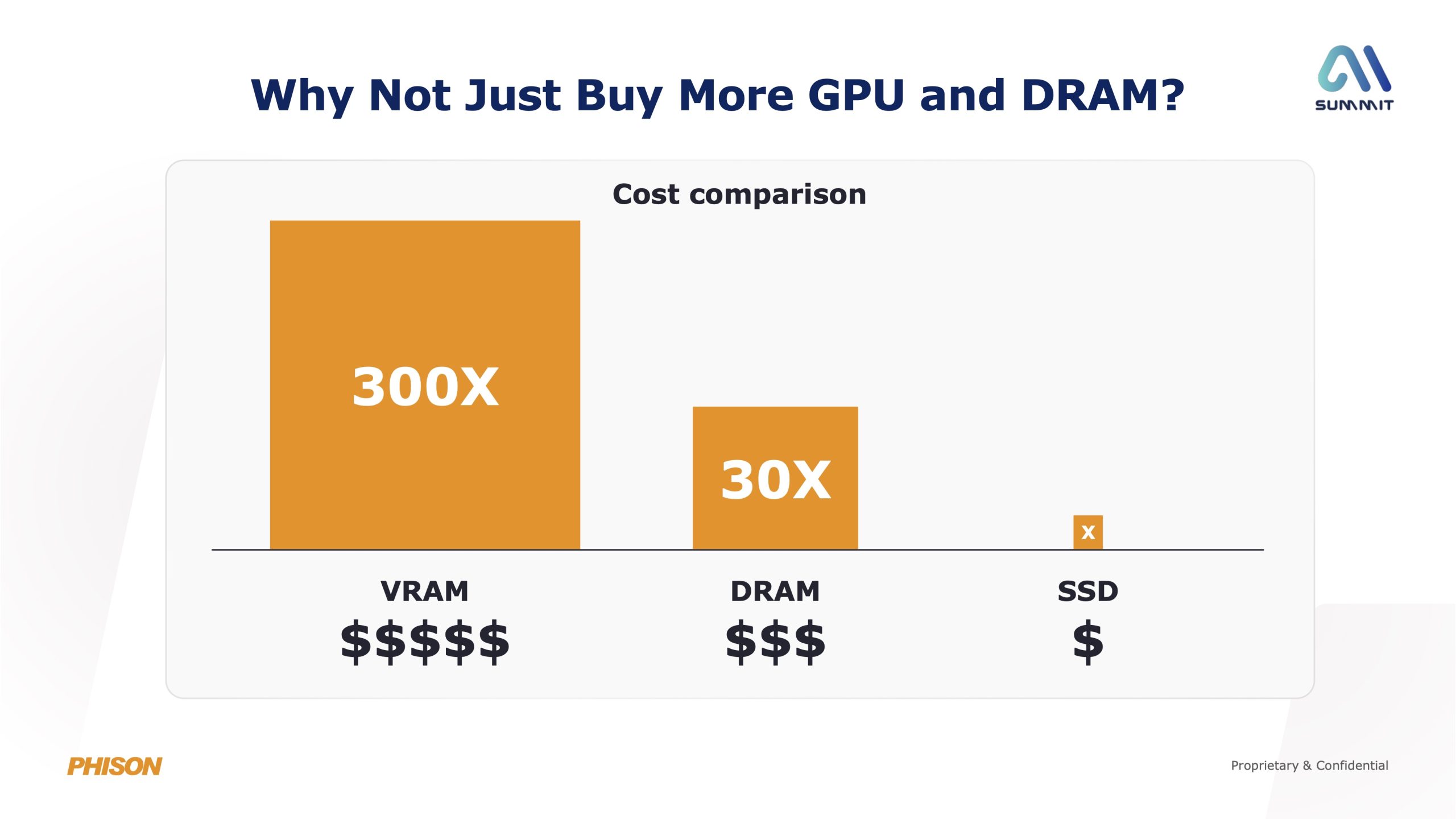
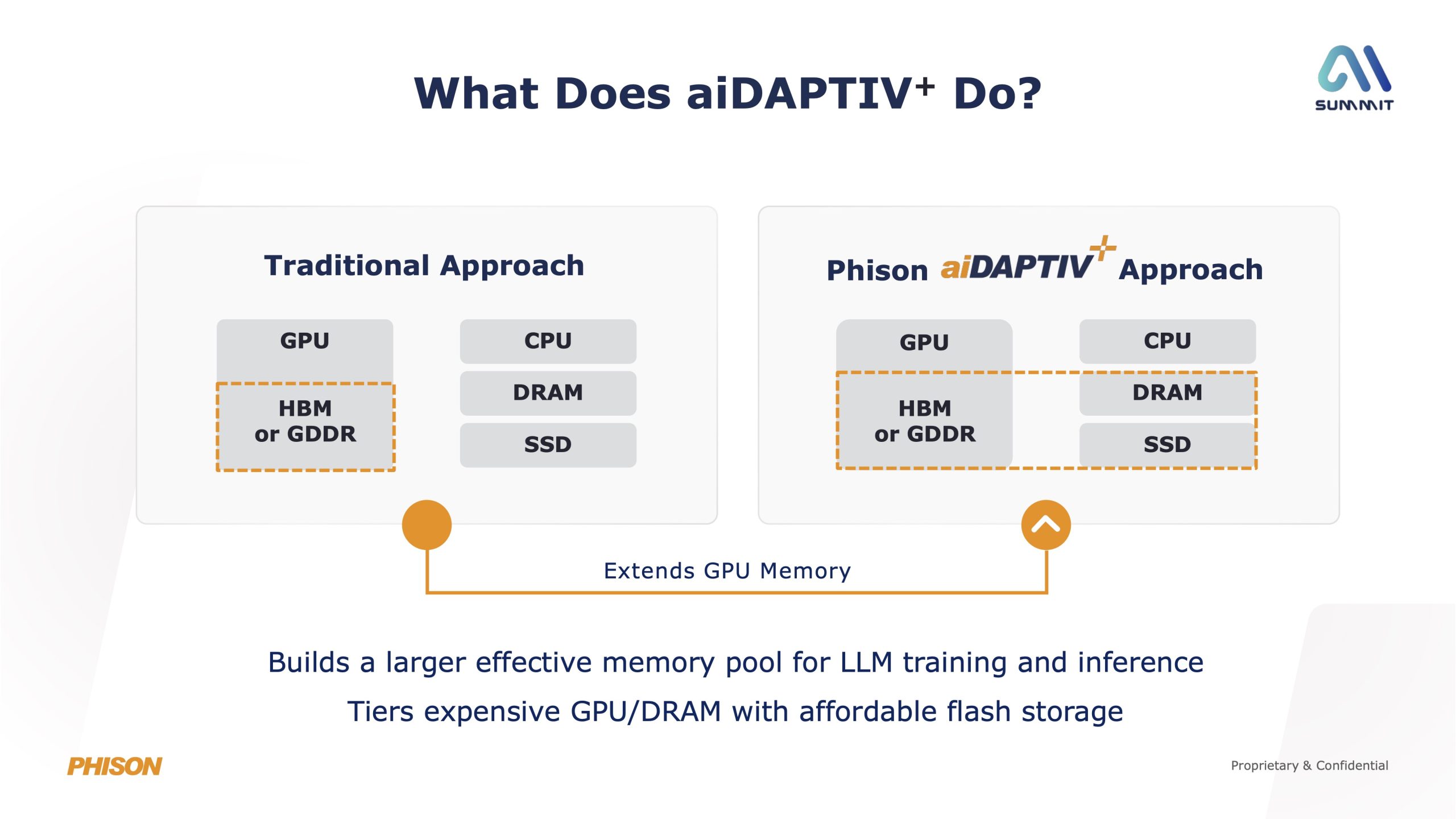
So, rather than relying on ever larger and more expensive GPUs – something we've already become well accustomed to in the gaming segment over the last few years – aiDAPTIV+ effectively builds a much larger memory pool by ‘tiering' GPU VRAM and system memory with NAND flash storage. This allows inactive AI data to be offloaded to SSDs, freeing up the properly fast memory for active workloads, while also significantly reducing cost compared to scaling VRAM or DRAM alone.

Now, at CES 2026, Phison has expanded aiDAPTIV+ beyond high-end AI workstations, making it a much more viable technology, given support has been added for ‘integrated GPU architectures', so mobile platforms – including laptops, desktops, workstations and small-form-factor PCs using both discrete and integrated GPUs – can now make use of the tech.

Phison claims that, for Mixture of Experts (MoE) inference processing, ‘a 120B parameter can now be handled with 32GB of DRAM' rather than 96GB that would otherwise be required with, what the company calls, ‘traditional approaches'.
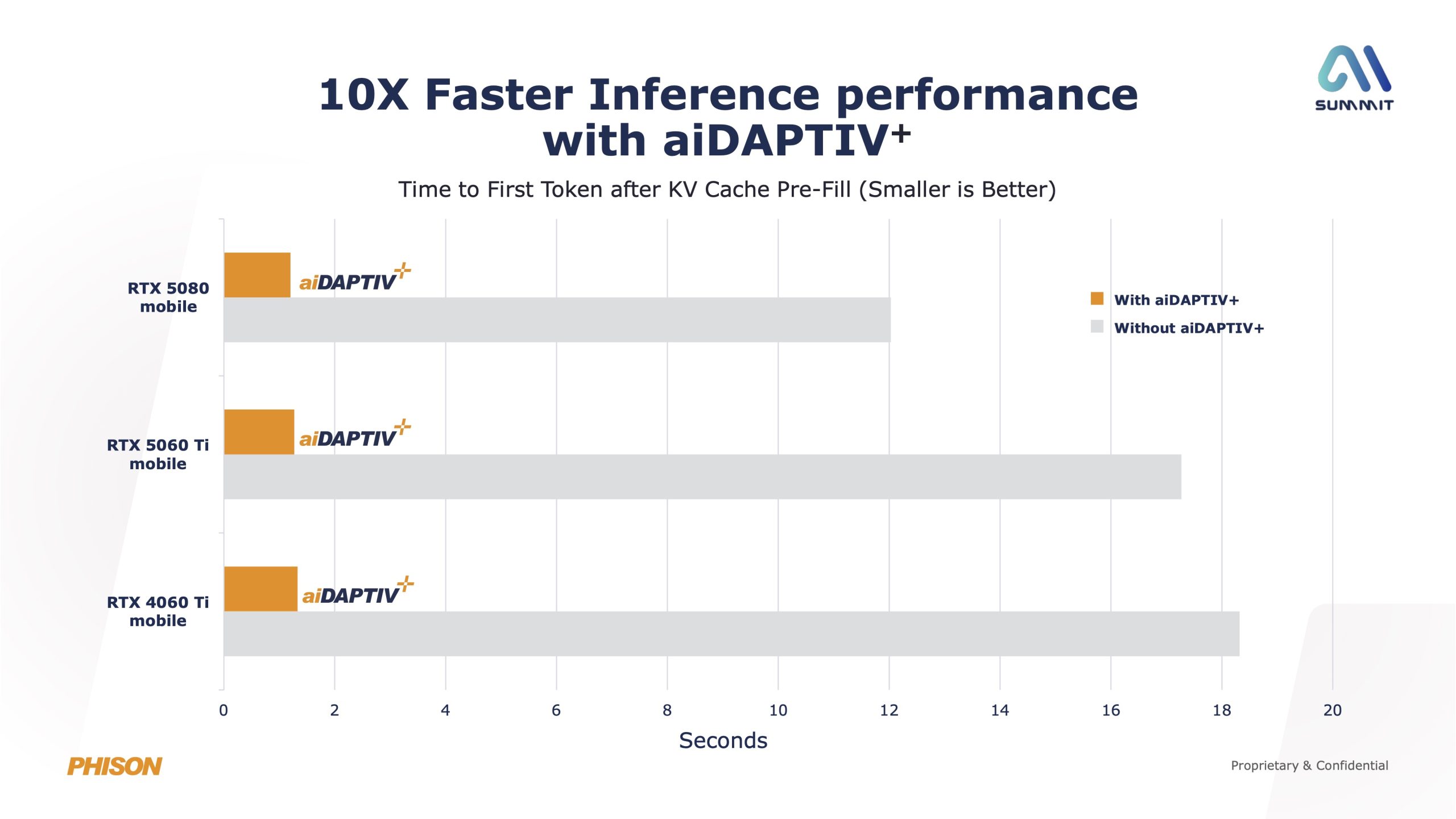
On top of that, aiDAPTIV+ addresses GPU KV cache limitations by moving older context data out of VRAM and into flash-based cache, allowing it to be reused instead of recomputed. According to Phison's presentation, this can deliver up to a 10x improvement in time-to-first-token for long prompts, improving responsiveness across a range of AI workloads.


Finally, Phison showed off a number of aiDAPTIV+ concept demos at CES 2026, including systems from brands more familiar to the typical KitGuru reader, including Acer, ASUS, MSI and Corsair. While there is clearly still work to be done, the demos give us a glimpse of what it would mean to bring practical AI acceleration to more mainstream systems, rather than relying on cloud-based solutions.
KitGuru says: It's an interesting technology that makes a lot of sense on paper. Let's see how things develop over the next few months.
