







The NVIDIA Quadro GP100 is a monster card released alongside the Quadro P4000 and P2000. Superficially, it looks similar to the almost-as-expensive P6000, requiring two slots for installation, and three blanking plate slots if you install the included external stereo connector bracket.
The dual-slot format allows it to offer the same four full-sized DisplayPort connections and a DVI-I port. It's also based on the Pascal GPU generation, like the P6000. The GP100 consumes slightly less power than the P6000 – 235W rather than 250W. But this is still a thirsty card (although not quite so much as AMD's latest top-end Vega graphics cards).
In some respects, the GP100 is slightly less well endowed than the P6000, which is curious considering how much more it costs. For a start, although the total of 3,584 CUDA cores is huge – 1,024 more than the P5000, and exactly twice that of the P4000 – the P6000 actually boasts 3,840. You also only get 16GB of memory with the GP100, where the P6000 offers 24GB. So what are you getting for the £1,700 extra the GP100 costs over the P6000?
The answer lies in the High Bandwidth Memory we mentioned in the introduction to this review. Whereas the GDDR5X memory used in the P6000 uses a 384-bit bus, which is already pretty wide, the HBM2 used in the GP100 is on a 4,096-bit bus. However, although the bus is more than ten times wider, the memory architecture is different, so the bandwidth is not ten times greater. But it is still more than the P6000. Where the latter offers 480GB/sec of throughput, the GP100 offers 717GB/sec, which is also three times that of the P4000.
So the GP100 is specifically aimed at applications requiring maximum memory bandwidth, and you can further accentuate this by connecting two together using NVIDIA's NVLink (which was included in our Workstation Specialists test system). This pools the memory for use by both graphics cards, allowing them to share a 32GB pool of extremely fast memory.
NVLink 2.0 promises bandwidth 5 to 12 times greater than PCI Express Gen 3. The maximum theoretical bandwidth is 150GB/sec in each direction, so not as fast at the HBM2 memory itself but only five times slower, where PCI Express Gen 3 with 16 lanes only provides 32GB/sec.
This means that in a multi-card setup, if one GPU needs data already loaded into the other card's memory, it can load it directly over NVLink much more quickly than from system memory over PCI Express.
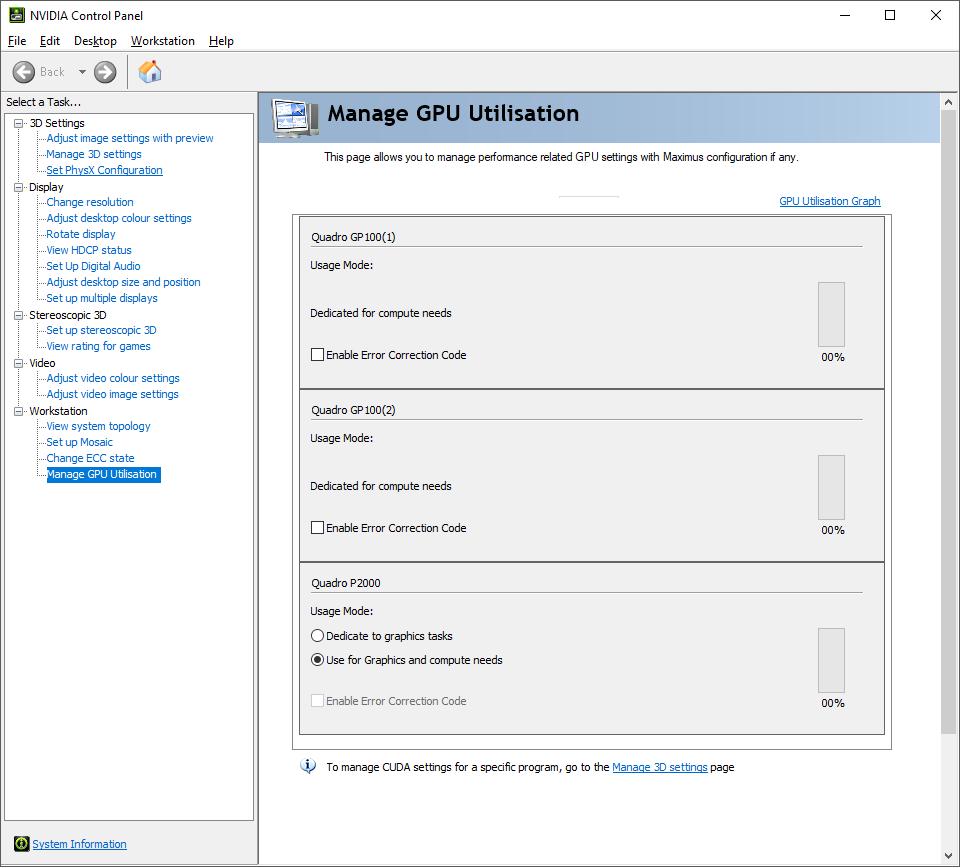
Our sample NVIDIA Quadro GP100s were configured exclusively for GPGPU work, as you can see from the NVIDIA Control Panel screenshot above. You can still plug monitor cables into them and these will work, but the NVIDIA Quadro P2000 will be doing the graphics acceleration and then sending the results to whichever card is attached to the screen over PCI Express, reducing performance.
In this configuration, the GP100s are intended to be very expensive, but very powerful, co-processors for CUDA- or OpenCL-based GPGPU work.

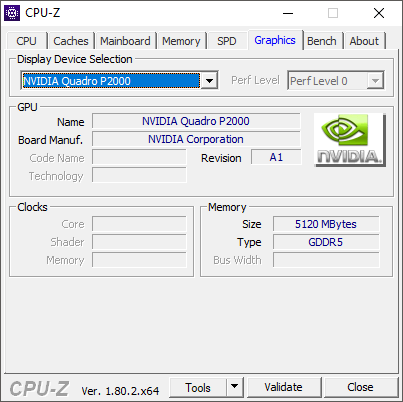
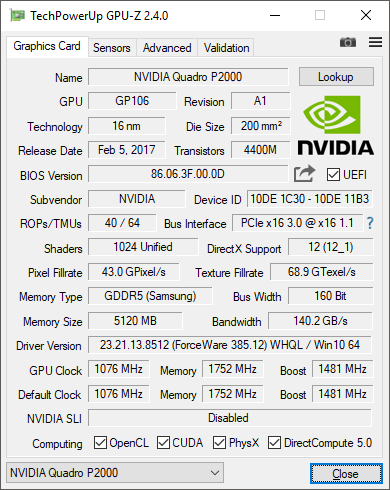
The Quadro P2000, despite being a mid-range card, is still pretty decent, with 1,024 CUDA cores running at 1,076MHz and 5GB of GDDR5 memory providing 140.2GB/sec of bandwidth. But it's a pale shadow compared to the GP100s, and is only there to provide graphics display and reasonable real-time 3D modelling acceleration.
So let's turn to look at where this system's strengths and weaknesses lie when it comes to performance.

But can it run minecraft
https://uploads.disquscdn.com/images/d35af349501f359d6bd115b13674892c3cee26f1099902e01a6ea61eea2b39de.jpg
This is such a stupid choice of parts. #1 The X99 platform, there is both the x299, and the Xeon platform which would be more suitable. #2 The Corsair H100i, which should be at least the H115i or preferably an NZXT or EVGA CLC 280 cooler, both of which are significantly better and quieter. #3 the RAM should be ECC in a workstation build, further pointing towards Xeon/Epyc as a platform base rather than x99. #4 The PSU in a £17k build should be as good as possible, ie a titanium rated one such as the Corsair AXi 1500 or Silverstone Prime Titanium 1000, as saving £50 on installing a platinum PSU doesn’t make sense at this budget. #5 I really think that while the 960 evo is great, in a *17k* build, the pro is a much more sensible option, also 250gb is pathetic.
I see so much of these high end builds, which aren’t really thought through, when they really should be, if made by a professional company. Of course this PC is still *good*, as the components are excellent, but it is not *great* because the components are not appropriate for the budget and use scenario.
Edit, it’s a flipping 18k build and they’re using an out of date platform as a base and sub ideal components… wow.
( ͡° ͜ʖ ͡°)
Check these systems out instead: https://www.kitguru.net/desktop-pc/james-morris/armari-amd-ryzen-threadripper-1950x-versus-intel-core-i9-7980xe-shootout/
https://uk.pcpartpicker.com/user/davengerdann/saved/ I know how to build systems, thanks anyway.
Never said you didn’t… I was merely (and brazenly) directing you towards another article I wrote! ?
Dainel. Fuck if ever there was an elitist you made the dictionary definition. Kick the hell back dude. You’re in the Metaverse.