

LuxMark 3.1
OpenCL is a platform for harnessing GPU power for activities other than real-time 3D rendering to screen, also known as GPGPU. Unlike NVIDIA's CUDA platform, OpenCL is open source and can be ported to anything with processing power. So drivers are available for CPUs as well, both from Intel and AMD.
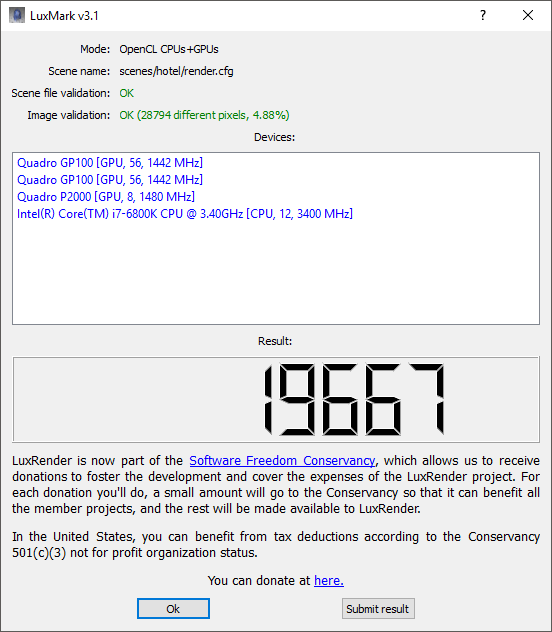
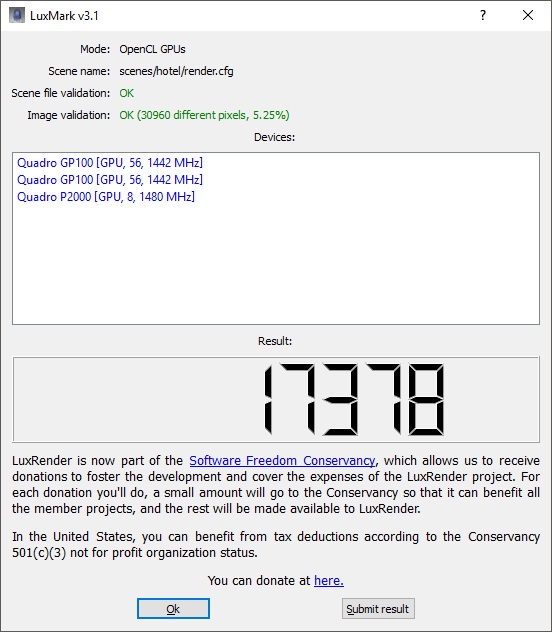
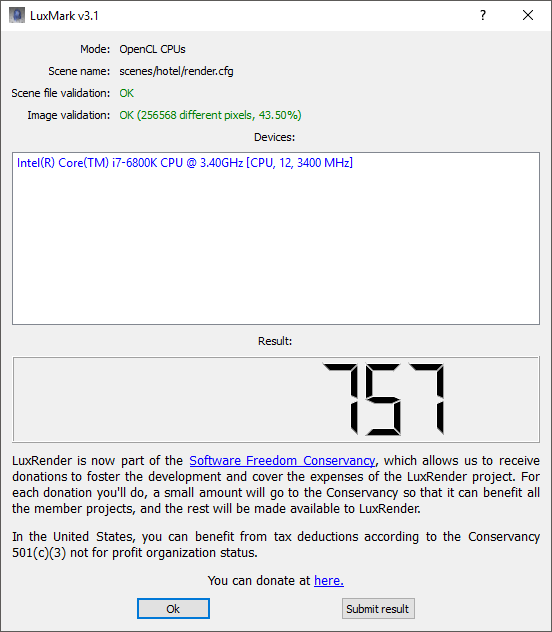
A popular tool for testing OpenCL performance is LuxMark. We haven't run this on many workstations before, so we only have one comparison amongst our past reviews. We ran the Sala scene on CPU only, GPU only, and then both.
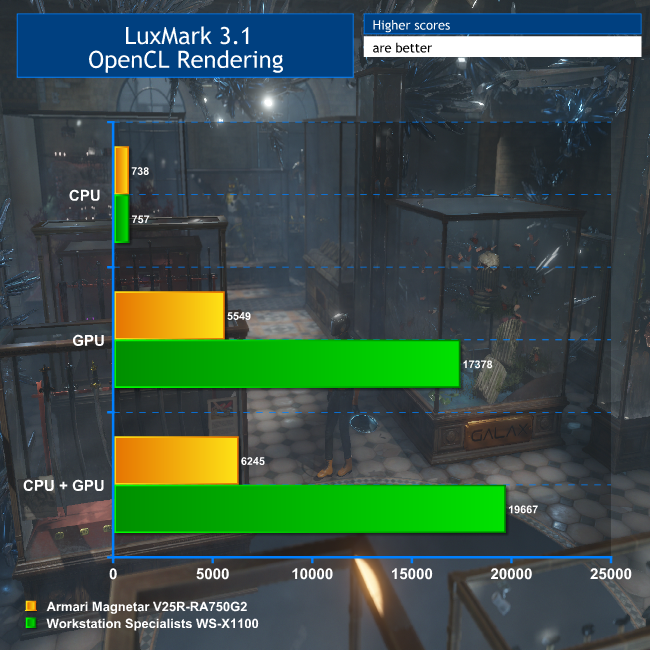
For this test, we only had results from the Armari Magnetar V25R for comparison. But as this system contained the AMD Radeon Pro Duo, a dual-GPU graphics card also tailored for GPGPU rendering, it makes a valid one to compare with, albeit much cheaper. In this test, the six-core Intel Core i7 6800K in the WS-X1100 is a little better for OpenCL than the eight-core AMD Ryzen 7 1800X in the Armari system.
But this is overshadowed by the results when the GPUs' OpenCL capabilities are brought to bear. The AMD Radeon Pro Duo is no slouch in this department, and for the money it's still a pretty valid option.
But the twin NVIDIA Quadro GP100 cards in the WS-X1100 blow it completely out of the water, providing more than three times the OpenCL grunt. For any application that can make real use of OpenCL acceleration, the NVIDIA Quadro GP100 has phenomenal performance on offer.
LuxMark is a synthetic benchmark – it doesn't correspond directly to an application actually used in a production environment. It also uses OpenCL, the GPGPU API that is openly available to all hardware with drivers to run it.
But NVIDIA has its own proprietary GPGPU API called CUDA, which stands for Compute Unified Device Architecture. This name makes it sound as generally available as OpenCL, but in fact only NVIDIA graphics cards support it.
Despite this proprietary nature, CUDA has arguably garnered more support than OpenCL to begin with. Adobe added CUDA acceleration to its effects filters and Mercury Playback Engine some years ago, with OpenCL added more recently. There are a number of CUDA-enhanced 3D renderers out there, such as Octane Render and Redshift.
The full list can be found on NVIDIA's website. But one of the most popular renderers, which plugs into a wide range of 3D content creation applications including all the main contenders, is V-Ray.
V-Ray Benchmark
V-Ray's application support is extensive, with plug-ins for Autodesk 3ds Max and Maya, Rhino, Maxon Cinema 4D, NUKE and Blender amongst others. You can learn more about it on the Chaos Group website. V-Ray has been used to render effects in a huge number of high-end productions, with recent notable examples being Fast & Furious 8: The Fate of the Furious and Game of Thrones. If you think Daenerys's dragons look good, even now one of them has (spoiler alert) joined the wrong side, then you have the quality of the V-Ray renderer partly to thank for that.
However, particularly useful for our needs here, there is a V-Ray benchmark that has been widely available for a while, based on the core V-Ray engine, including CPU and CUDA GPU support. It renders two different scenes, one on the CPUs only, one on the GPUs only. We ran this on the WS-X1100.

Out of context, these figures probably don't mean very much. But since this is a public benchmark that includes a facility to upload to the Chaos Group website, you can see all the CPU results and GPU results there.
The current top CPU score was obtained with a system sporting 192 cores, so naturally the WS-X1100 is nowhere in comparison. But the top GPU score was obtained with four NVIDIA Quadro GP100 cards, and at 14.359 seconds is only 32 per cent faster.
In fact, our result of 19 seconds would place the WS-X1100 in the current top 20 systems in the world for the V-Ray Benchmark. So this is a SERIOUSLY fast system for CUDA-based GPGPU work. If you're outputting 3D to a V-Ray renderer, the performance could well be worth the huge outlay.

But can it run minecraft
https://uploads.disquscdn.com/images/d35af349501f359d6bd115b13674892c3cee26f1099902e01a6ea61eea2b39de.jpg
This is such a stupid choice of parts. #1 The X99 platform, there is both the x299, and the Xeon platform which would be more suitable. #2 The Corsair H100i, which should be at least the H115i or preferably an NZXT or EVGA CLC 280 cooler, both of which are significantly better and quieter. #3 the RAM should be ECC in a workstation build, further pointing towards Xeon/Epyc as a platform base rather than x99. #4 The PSU in a £17k build should be as good as possible, ie a titanium rated one such as the Corsair AXi 1500 or Silverstone Prime Titanium 1000, as saving £50 on installing a platinum PSU doesn’t make sense at this budget. #5 I really think that while the 960 evo is great, in a *17k* build, the pro is a much more sensible option, also 250gb is pathetic.
I see so much of these high end builds, which aren’t really thought through, when they really should be, if made by a professional company. Of course this PC is still *good*, as the components are excellent, but it is not *great* because the components are not appropriate for the budget and use scenario.
Edit, it’s a flipping 18k build and they’re using an out of date platform as a base and sub ideal components… wow.
( ͡° ͜ʖ ͡°)
Check these systems out instead: https://www.kitguru.net/desktop-pc/james-morris/armari-amd-ryzen-threadripper-1950x-versus-intel-core-i9-7980xe-shootout/
https://uk.pcpartpicker.com/user/davengerdann/saved/ I know how to build systems, thanks anyway.
Never said you didn’t… I was merely (and brazenly) directing you towards another article I wrote! ?
Dainel. Fuck if ever there was an elitist you made the dictionary definition. Kick the hell back dude. You’re in the Metaverse.