

RDNA 2 makes several key changes to the architecture compared to RDNA 1. Here we go over what you need to know.
We've mentioned the increased frequency on the previous page, and AMD claims that as the only company delivering both gaming CPUs and GPUs, it is ‘uniquely positioned' to leverage this position to further both teams.
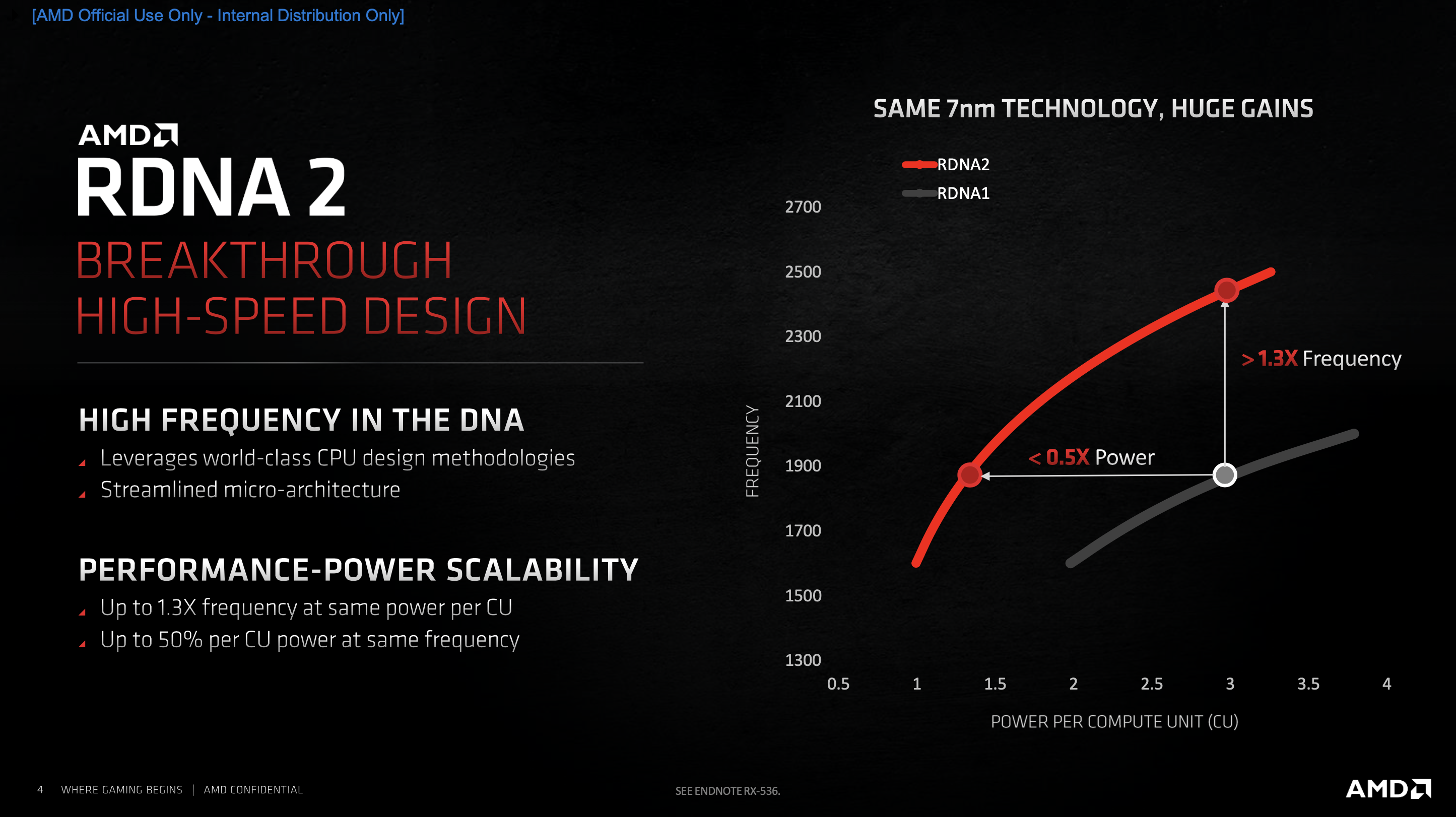
With RDNA 2, AMD says it incorporated design methodologies from the Zen CPU team while ‘streamlining the micro-architecture to achieve record frequencies'. Part of this comes as a result of optimising frequencies across the whole voltage range for increased scalability.
AMD says this allows RDNA 2 to offer approximately 30% increased frequency at the same CU power compared to RDNA, or cut power by around 50% at the same frequency – or anywhere in between. Michael Mantor, Chief GPU Architect at AMD, says ‘this level of increase and power reduction in the same process technology enabled us to double the CU count of Big Navi with a modest power increase.'


Part of this is a result of the huge changes that AMD claims the RDNA 2 CU has undergone to achieve that touted 30% higher performance at the same power compared to RDNA. The company highlights the difference machine learning can make for gaming, resulting in various mixed precision operations included within the design to accelerate these AI workloads.
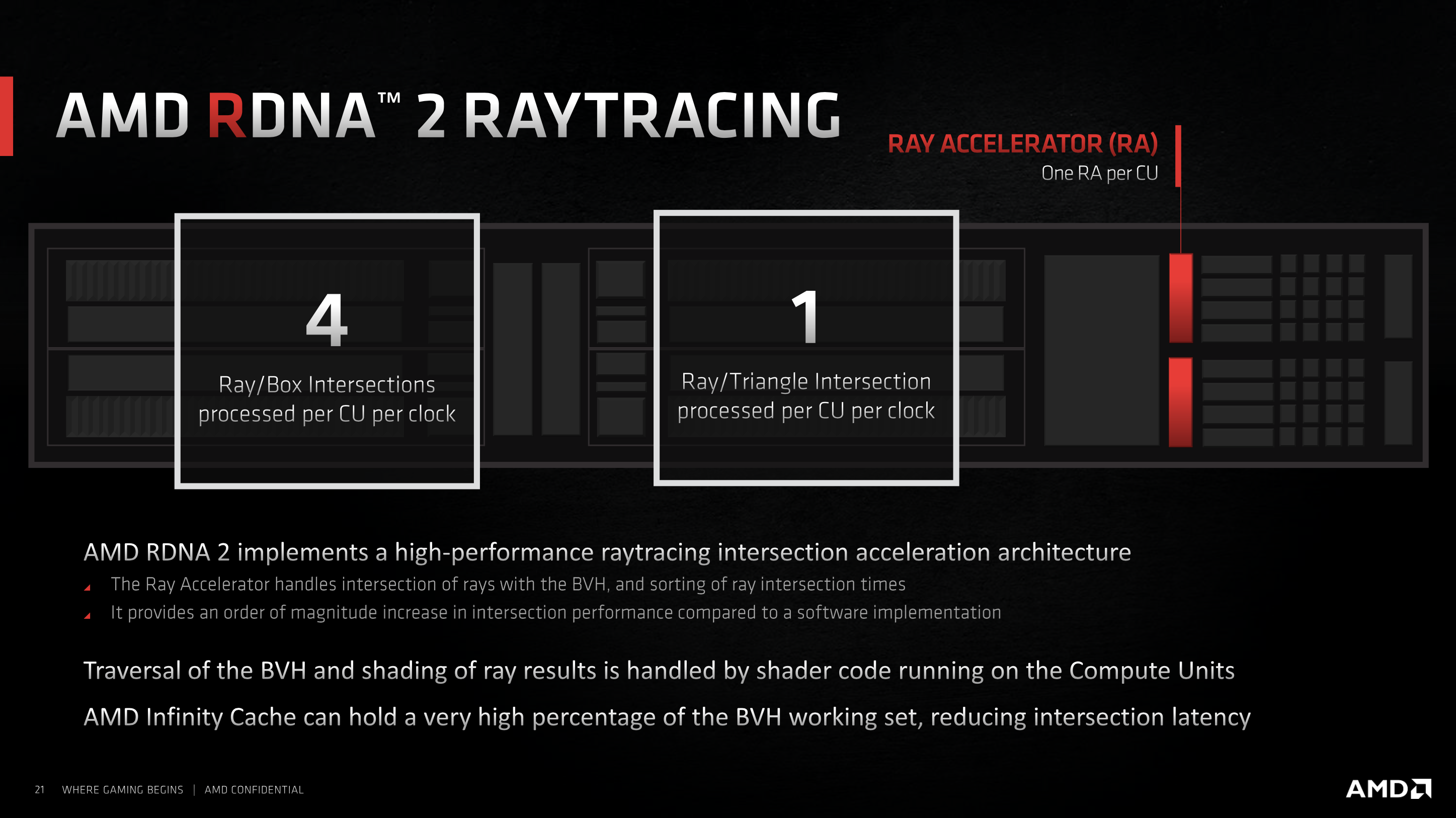
Each CU is also now home to one Ray Accelerator, the hardware responsible for handling the intersection of rays with the Bounding Volume Hierarchy (BVH). AMD says the Ray Accelerator can calculate up to 4 ray/box intersections or ray/triangle intersection every clock, and overall offers roughly 10 times the ray tracing performance than what shaders alone could achieve.
We asked AMD how the Ray Accelerators differed to Nvidia's RT Core, and have copied their response verbatim:
“In comparison to Nvidia's fully dedicated raytracing cores, the RDNA 2 Ray Accelerators are tightly integrated into the RDNA 2 CU, sharing much of the existing hardware that would be typically underutilized during raytracing passes. This enables RDNA 2 to experience the full benefits of hardware-accelerated ray tracing when ray tracing is being used, without having to pay the power and area costs of fully dedicated raytracing dark silicon for passes that do not use the raytracing hardware, or the power and area costs of the underutilized resources during the raytracing passes.
This allows RDNA™ 2 to dedicate more die area to functionality that help both raytracing and non-raytracing gaming performance (such as Infinity Cache) and to clock higher for a given power budget.
The final performance characteristics will depend on the game, the type of raytracing effects used and optimizations. However, we believe our Ray Accelerators along with other RDNA 2 enhancements such as frequency increase, CU count increase and Infinity Cache will help deliver visually stunning gameplay both with and without raytracing at native resolutions.”

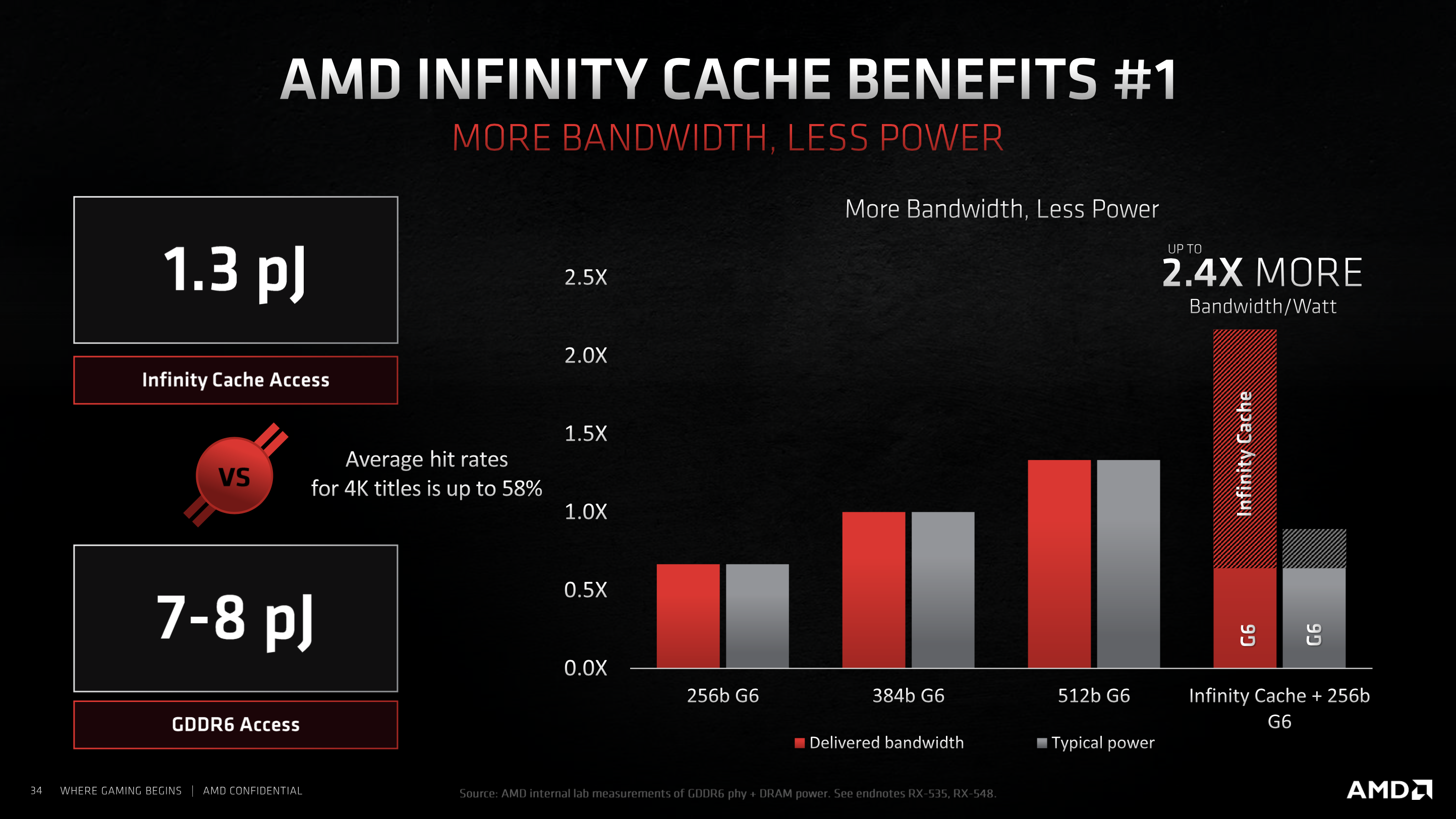


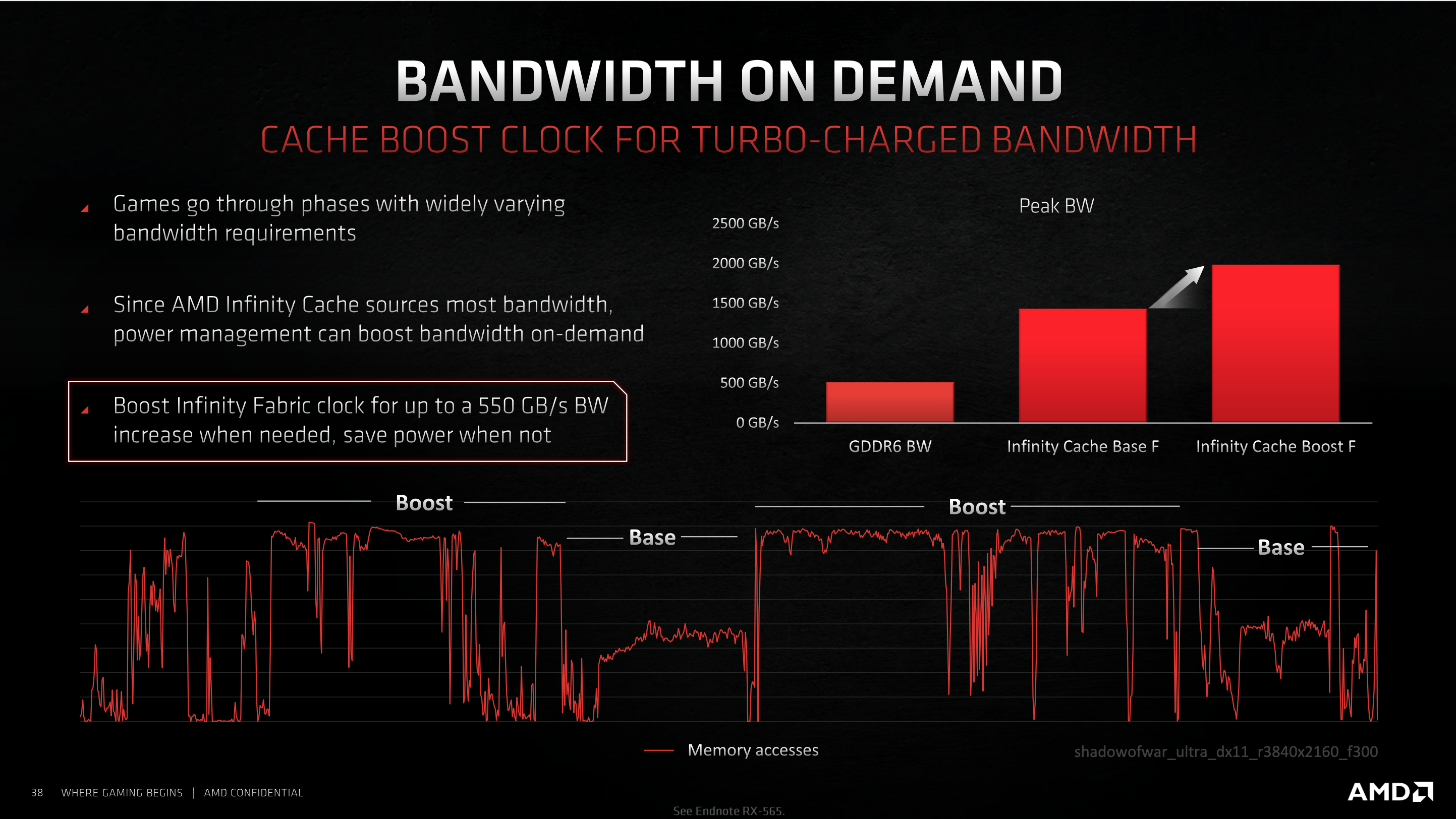
AMD's Infinity Cache has also garnered significant attention. AMD implemented this solution to deliver enough bandwidth to the increased CU count, running at higher frequencies, as it claims these two changes would have otherwise required a 2.6x increased to bandwidth without starving the GPU – something it claims would have been hugely impractical due to the physical size and power requirements.
This solution combines AMD's ‘industry leading' cache from its EPYC sever designs, with an ‘outrageously fast on-die Infinity Fabric', according to Samuel Naffzifger, Corporate Fellow and Product Technology Architect. Each of the 16 channels in the Infinity Fabric provides 64B of data per clock, delivering 1024B data per clock at up to 1.94GHz. Naffziger claims this delivers up to 4 times the bandwidth of existing GDDR6 solutions and provides sufficient bandwidth to the engine.
With this on-die cache, AMD says it can deliver frame data at lower energy per bit when compared to a solution delivering the equivalent bandwidth via traditional means. With the Infinity Cache, AMD claims it can deliver over double the bandwidth of a 384-bit GDDR6 interface, with minimal increases to power. All told, the company claims up to 2.4x increased bandwidth per Watt.
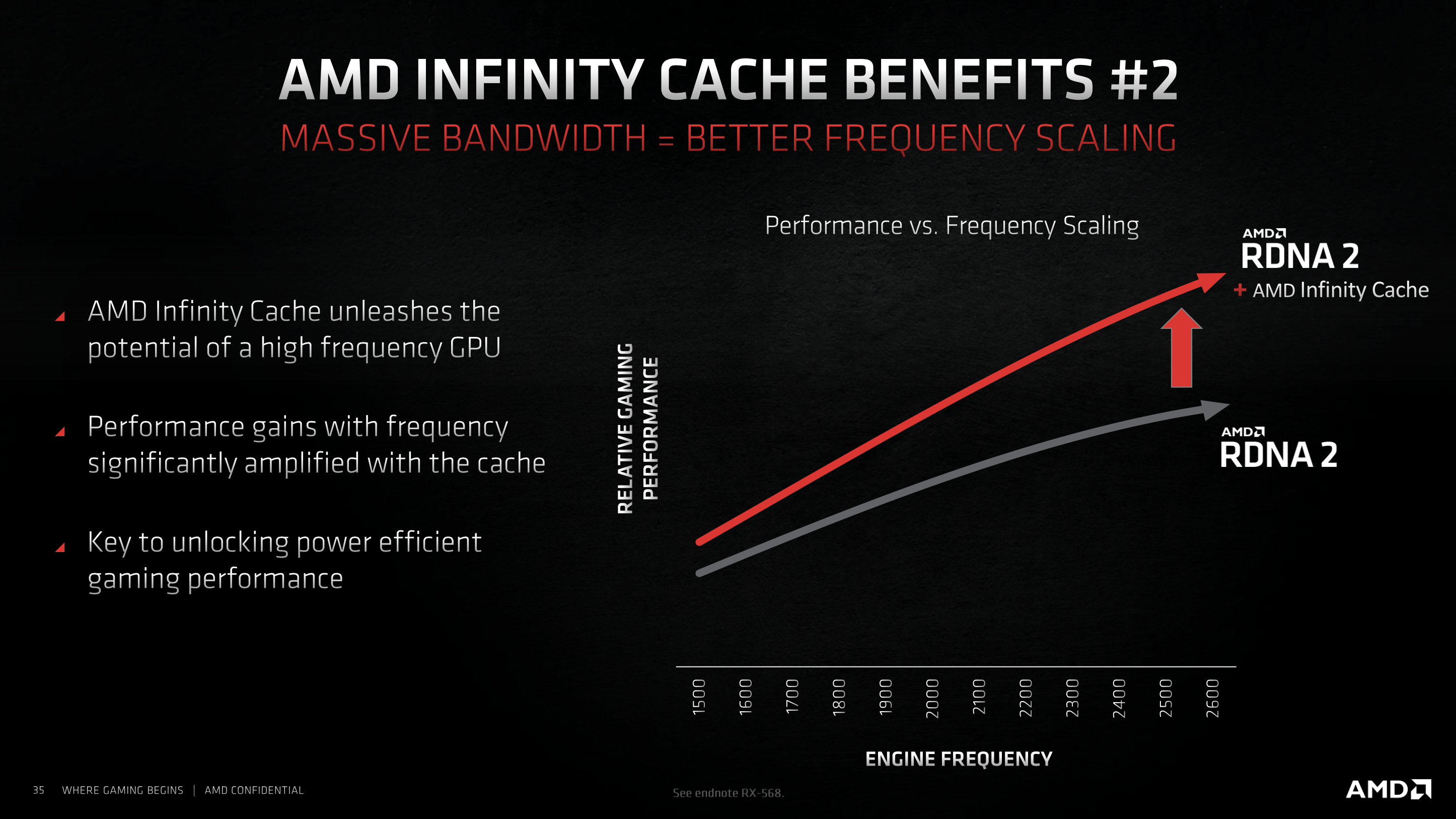
Additionally, the Infinity Cache enables AMD to better scale its performance with the increased GPU frequency. Without the Infinity Cache, the relative gains from increasing core clocks diminish significantly at the higher frequencies.


Lastly we touch on Smart Access Memory. This made the news recently as Nvidia has said it is working on implementing the same technology. For AMD, Smart Access Memory (SAM) refers to the CPU's abilities to better access GPU VRAM. Currently, the CPU only has access to 256MB of GPU memory at a time, but with its Ryzen 5000 series CPUs, 500-series motherboards and RX 6000-series GPUs, AMD has removed this limitation – the CPU now has full access to the high-speed GPU memory.
While AMD has attracted some criticism for ‘locking' this feature to its Ryzen 5000 series CPUs, the company issued a statement clarifying the situation, which we have copied here:
“As the only company offering high performance gaming CPUs and GPUs, AMD is in a unique position to deliver incredible PC gaming experiences. With AMD Smart Access Memory , we have designed, optimized and validated both hardware and software technologies with all combinations of Ryzen 5000 Series processors, Radeon RX 6000 Series graphics cards, AMD 500 Series motherboards and the latest drivers and BIOS at launch. We believe this pairing unlocks maximum platform performance. Smart Access Memory is built on features of the PCIe standard and firmware standards (Resizable BAR), and was developed through extensive validation and platform optimization. We welcome the opportunity to support other hardware vendors in their efforts as part of our ongoing commitment to using common and open standards to improve gaming experiences.”
