

Nvidia claims that the Turing architecture ‘represents the biggest architectural leap forward in over a decade', so here we detail what's new with Turing – with a particular focus on technologies that will affect/improve your gaming experience.
Note: if you have come directly from our RTX 2080 Ti review, the information provided below is the same.
Turing GPUs
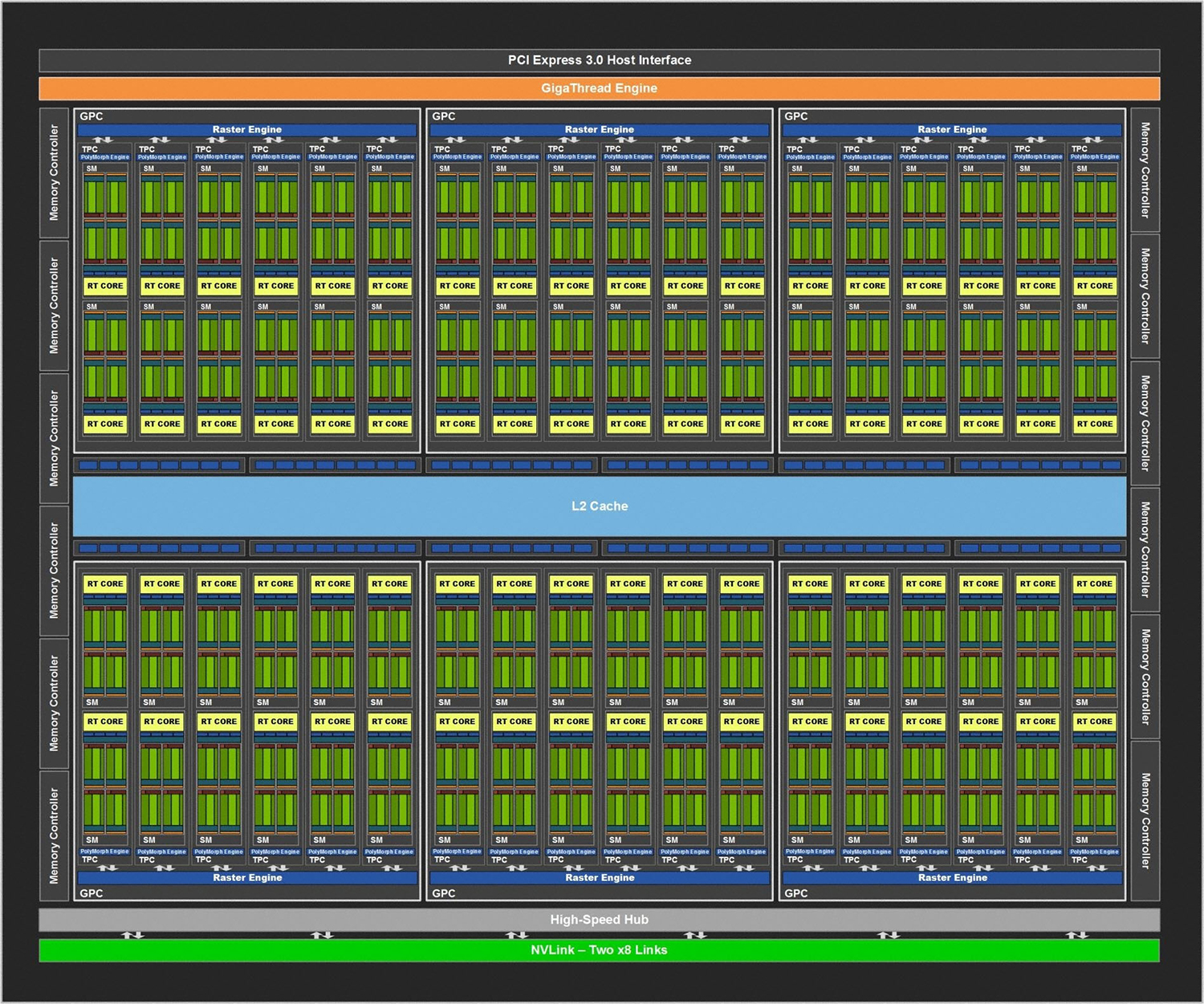
The first thing to note is that, currently, we have three Turing GPUs – TU102, TU104 and TU106. While the RTX 2080 Ti uses the TU102 GPU, it is not actually a full implementation of that chip. TU102, for instance, sports more CUDA cores, as well as a greater number of RT cores, Tensor cores and even an extra GB of memory.
For the sake of reference, however, the Turing architecture detailed below uses the full TU102 GPU as the basis for its explanation. The architecture obviously remains consistent with the TU104 (RTX 2080) and TU106 (RTX 2070) GPUs , but those GPUs are essentially cut-back versions of TU102.
Turing Steaming Multiprocessor (SM) and what it means for today's games
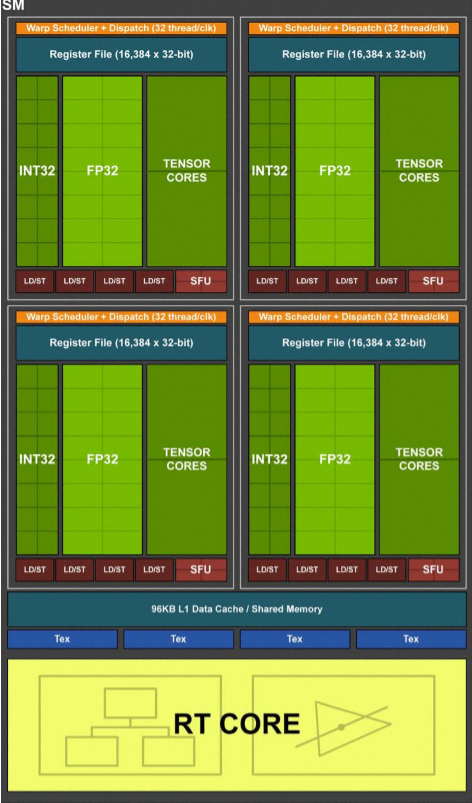
Compared to Pascal, the Turing SM sports quite a different design that builds on what we first saw with the Volta GV100 GPU. On the surface level, Turing includes two SMs per Texture Processing Cluster (TPC), with each SM housing 64 FP32 cores and 64 INT32 cores. On top of that, a Turing SM also includes 8 Tensor Cores and one RT core.
Pascal, on the other hand, has just 1 SM per TPC, with 128 FP32 cores within each SM, and obviously no Tensor or TR cores being present either.
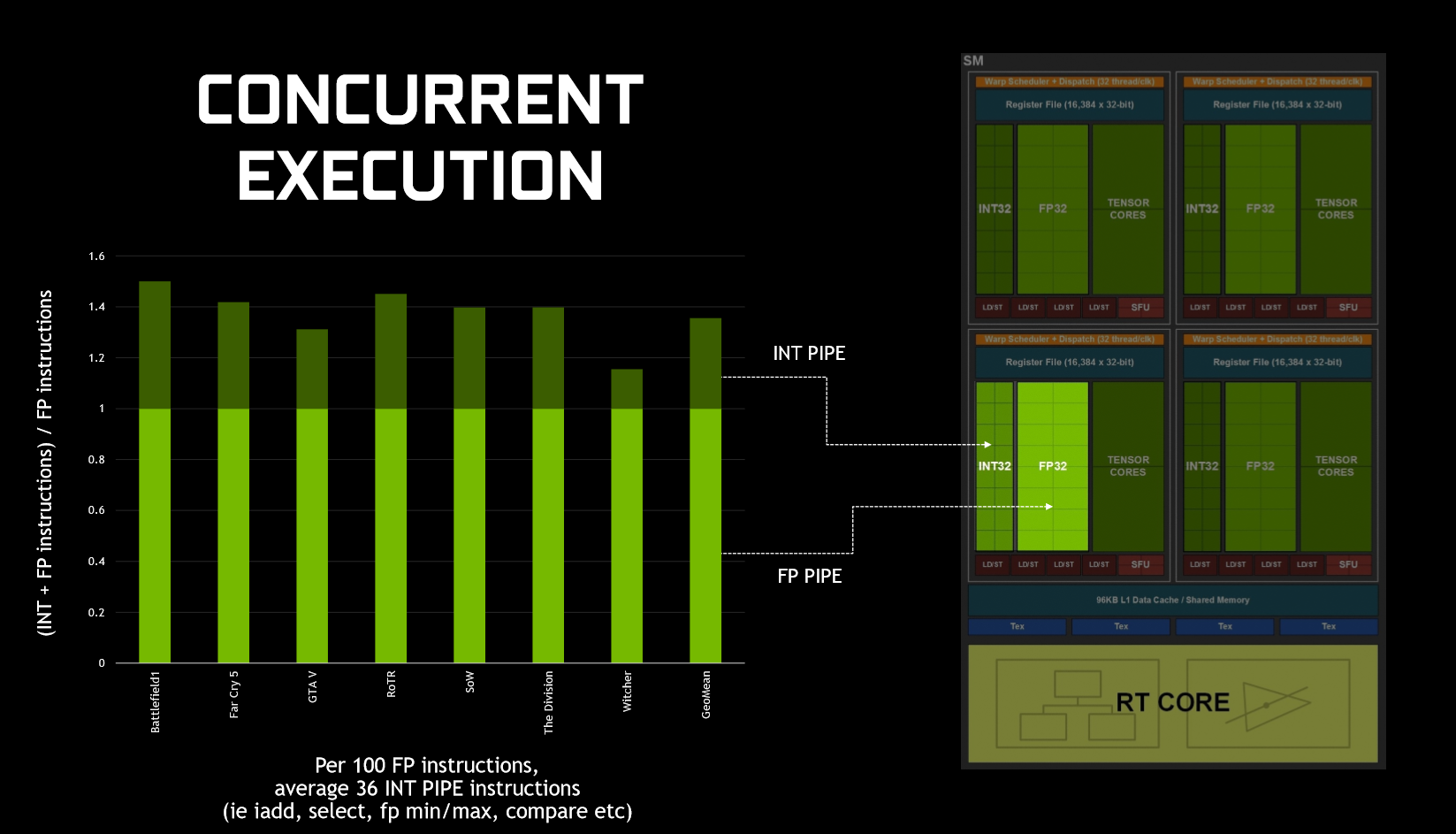
What makes Turing significant for today's games, is how it executes datapaths. That's because, in game, GPUs typically execute both floating point (FP) arithmetic instructions, as well as simpler integer instructions. To demonstrate this, Nvidia claims that we ‘see about 36 additional integer pipe instructions for every 100 floating point instructions', although this figure will vary depending on what application/game you run.
Previous architectures – like Pascal – could not run both FP and integer instructions simultaneously – integer instructions would instead force the FP datapath to sit idle. As we've already mentioned, however, Turing includes FP and integer cores within the same SM, and this means the GPU can execute integer instructions alongside (in parallel with) the FP maths.
In a nutshell, this should mean noticeably better performance while gaming as FP and integer instructions can be executed in parallel, when previously integer instructions stopped FP instructions executing.
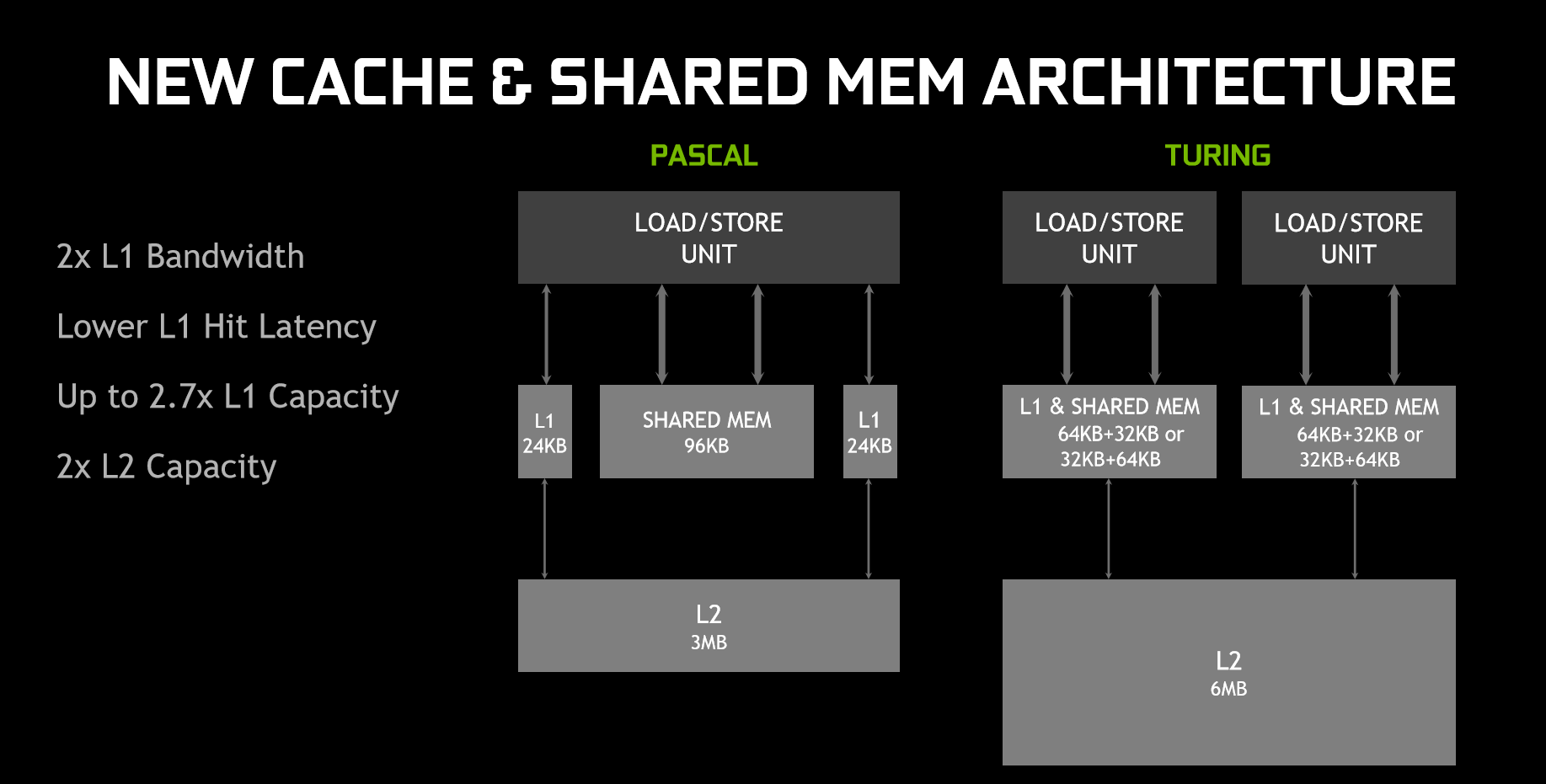
On top of that, Turing has also rejigged the memory architecture. In essence, the memory architecture is now unified, meaning the L1 (level 1) cache can ‘leverage resources', leading to twice the bandwidth per Texture Processing Cluster (TPC) when compared to Pascal. Memory can even be reconfigured when shared memory is not utilising its full capacity – for instance, L1 memory can expand/reduce to 64KB or 32KB respectively, with the former allowing less shared memory per SM, while the latter allows for more shared memory.
In sum, Nvidia claims the memory and parallel execution improvements equates to 50% improved performance per CUDA core (versus Pascal.) For real-world performance gains, this review will obviously document that later.
GDDR6

New with Turing is also GDDR6 memory – the first time such VRAM has ever been used with a GPU. With GDDR6, all three Turing GPUs can deliver 14 Gbps signalling rates, despite power efficiency improving 20% over GDDR5X (which was used with GTX 1080 and 1080 Ti). This also required Nvidia to re-work the memory sub-system, resulting in multiple improvements including a claimed 40% reduction in signal crosstalk.
Alongside this, Turing has built on Pascal's memory compression algorithms, which actually further improves memory bandwidth beyond the speeds that moving to GDDR6 itself brings. Nvidia claims this compression (or traffic reduction) as well as the speed benefit of moving to GDDR6, results in 50% higher effective bandwidth compared to Pascal.
NVLink
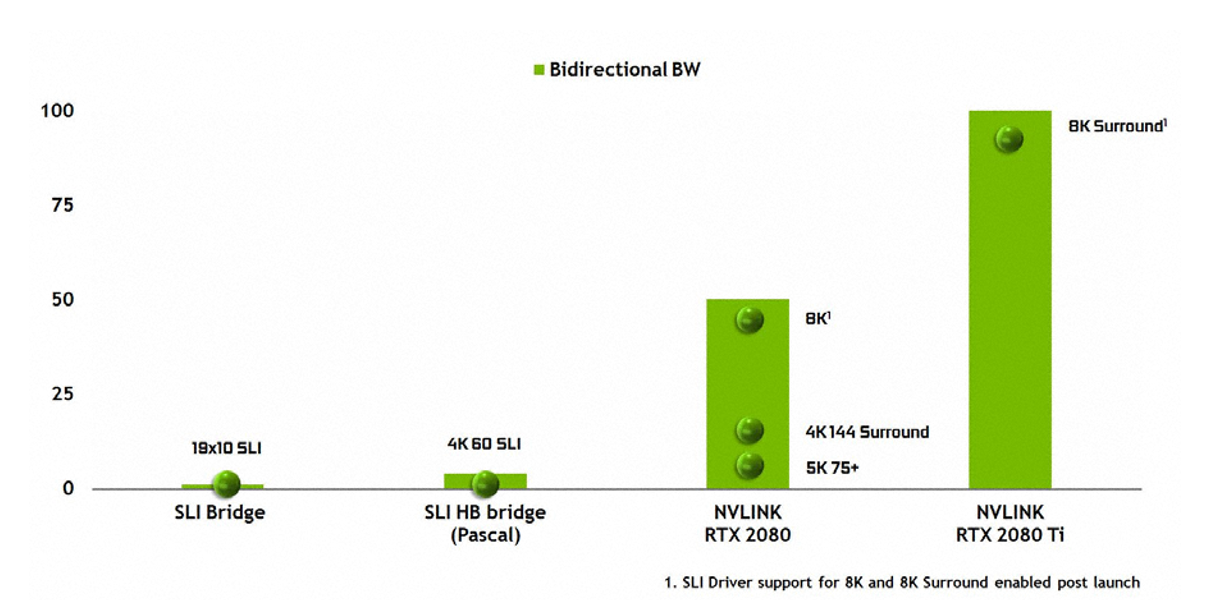
The last change to discuss here is NVLink. As we noted in our unboxing video, the traditional SLI finger has changed. Previous Nvidia GPUs used a Multiple Input/Output (MIO) interface with SLI, whereas Turing (TU102 and TU104 only) uses NVLink instead of MIO, while GPU-to-GPU data transfers use the PCIe interface.
TU102 provides two x8 second-gen NVLinks, while TU104 provides just one. Each link provides 50GB/sec bidirectional bandwidth (or 25GB/sec per direction), so TU102 will provide up to 100GB/sec bidirectionally.
Nvidia did not provide an exact figure of bandwidth for SLI used with Pascal GPUs, but from the graph above NVLink clearly provides a huge boost to bandwidth figures. It will be fascinating to test this with games in the near future.
Do remember, though, that NVLink is only supported with TU102 and TU104 – RTX 2080 Ti and RTX 2080 – so RTX 2070 buyers will not be able to take advantage of this technology.
