

The Nvidia GTX 1080 is based on the Pascal GPU architecture that was first introduced in the high end, datacenter class GP100 GPU. Nvidia's new Pascal GPU (GP104) is designed to deal with upcoming Direct X 12 games and Vulkan graphics. Nvidia will be placing a lot of focus on VR going forward as well.
Nvidia have been at the forefront of power efficiency for some time now, I was a huge fan of the Maxwell architecture and I still remember the first GTX750 ti I reviewed way back in February 2014.
This was the first Maxwell card we tested on launch day and it delivered solid 1080p performance, all without even requiring a single PCIe power connector – and best of all it required only 60 watts when gaming. When the higher end Maxwell cards were released later in the year, Nvidia dominated the market.

The GTX 1080 is comprised of a whopping 7.2 billion transistors, including 2560 single precision CUDA Cores. It is built on the 16nm FinFET manufacturing process which will drive higher levels of performance while increasing power efficiency – critical when operating at very high clock speeds.
Nvidia Gameworks is a key focus for Nvidia although it would be fair to say that it has been the centre point of plenty of controversy over the last year. Nvidia state that the GTX 1080 performance with GameWorks libraries enable developers to ‘readily implement more interactive and cinematic experiences.' Nvidia claim that the Pascal architecture, 16nm FinFET manufacturing process and GDDR5X memory give the GTX1080 a total 70% lead over the previous GTX980 flagship.
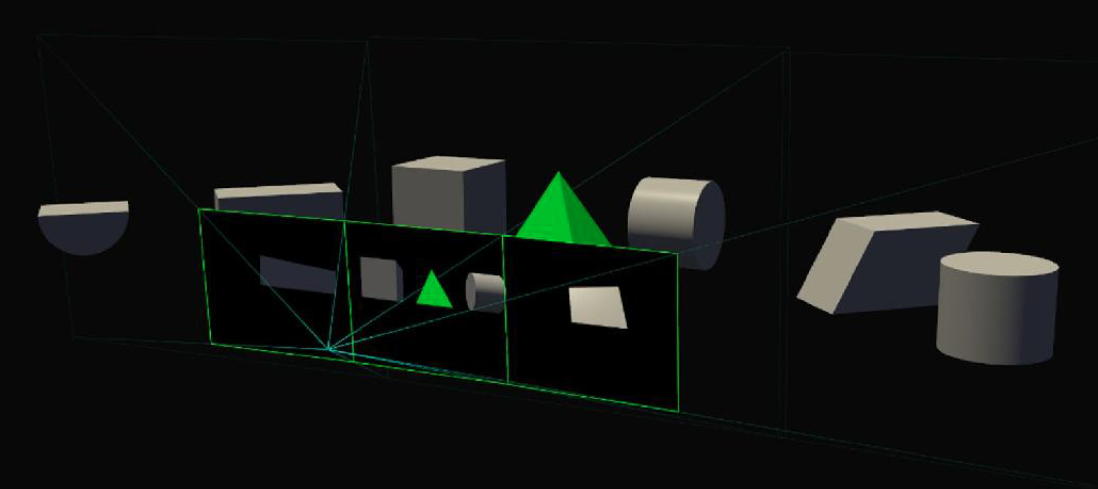
Perspective Surround is a new technology. It uses SMP to render a wider field of view and the correct image perspective, across all three monitors, with a single geometry pass.
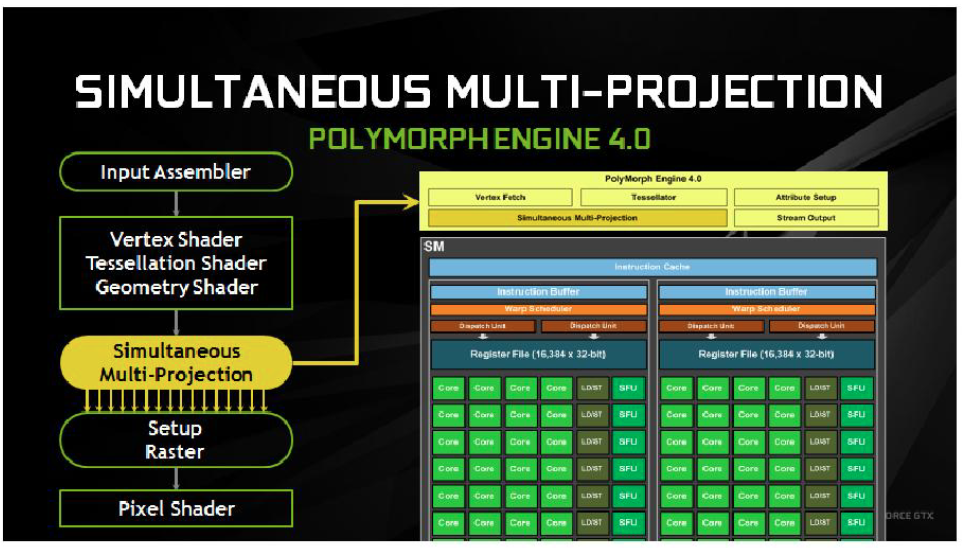
Nvidia have also developed a new Simultaneous Multi Projection technology, which for the first time allows the GPU to simultaneously map a single primitive onto up to sixteen different projections from the same viewpoint.

Each of these projections can be either mono or stereo and it will allow the GTX 1080 to accurately match the curved projection required for VR displays as well as the multiple projection angles required for surround display configurations.
Pascal graphics cards are based around different configurations of Graphics Processing Clusters (GPCs), Streaming Multiprocessors (SMs) and memory controllers. Each Streaming multiprocessor is paired up with a PolyMorph Engine that handles tessellation, vertex fetch, viewport transformation, perspective correction and vertex attribute setup. The GP104 PolyMorph Engine includes the Simultaneous Multi Projection unit discussed above. The combination of a SM plus one PolyMorph Engine is referred to as a TPC.

The GP104 powered GTX 1080 consists of four GPCs, twenty Pascal Streaming Multiprocessors and eight memory controllers. Inside the GTX 1080 each GPC ships with a dedicated raster engine and five SMs. Each of these SM's contains 128 CUDA Cores, 256kb of register file capacity, a 96KB shared memory unit, 48kb of total L1 cache storage and eight texture units.
The SM is critical, it is a highly parallel multiprocessor which can schedule warps (groups of 32 threads) to CUDA cores and other execution units within the SM. Almost all operations flow through the SM during the rendering pipeline. With 20 SM's listed, the GTX 1080 comprises 2560 CUDA cores and 160 texture units.
The GTX 1080 has eight 32 bit memory controllers (256 bit in total). Connected to each 32 bit memory controller are eight ROP units and 256kb of Level 2 cache. The full GP104 chip in the GTX 1080 has a total of 64 ROPs and 2,048kb of Level 2 cache.
| GPU | Geforce GTX 980 (Maxwell) |
Geforce GTX 1080 (Pascal) |
| Streaming Multiprocessors | 16 | 20 |
| CUDA Cores | 2048 | 2560 |
| Base Clock | 1126mhz | 1607mhz |
| GPU Boost Clock | 1216mhz | 1733mhz |
| GFLOPS | 4981 | 8873 |
| Texture Units | 128 | 160 |
| Texture fill-rate | 155.6 Gigatexels/Sec | 277.3 Gigatexels/Sec |
| Memory Clock (Data Rate) | 7,000 mhz | 10,000 mhz |
| Memory Bandwidth | 224 GB/sec | 320 GB/s |
| ROPs | 64 | 64 |
| L2 Cache size | 2048 KB | 2048KB |
| TDP | 165 watts | 180 watts |
| Transistors | 5.2 billion | 7.2 billion |
| Die Size | 398 mm2 | 314 mm2 |
| Manufacturing Process | 28nm | 16nm |
GDDR5X is a critical performance improvement that Nvidia wanted to bring with Pascal. It is a faster and more advanced interface standard, achieving 10 Gbps transfer rates, or roughly 100 picoseconds (ps) between data bits. Putting this into context, light travels at only an inch in a 100 ps time interval; the GDDR5X IO circuit has less than half that time available to sample a bit as it arrives, or the data will be lost as the bus transitions to a new set of values.
Coping with such a tremendous speed of operation required the development of a new IO circuit architecture. It took them years to implement. Nvidia have been focusing on reducing power consumption since early 2014, and with these new circuit developments and lower 1.35V GDDR5X standards, combined with process technologies this allowed for a 43% higher operating frequency without increasing power demand.
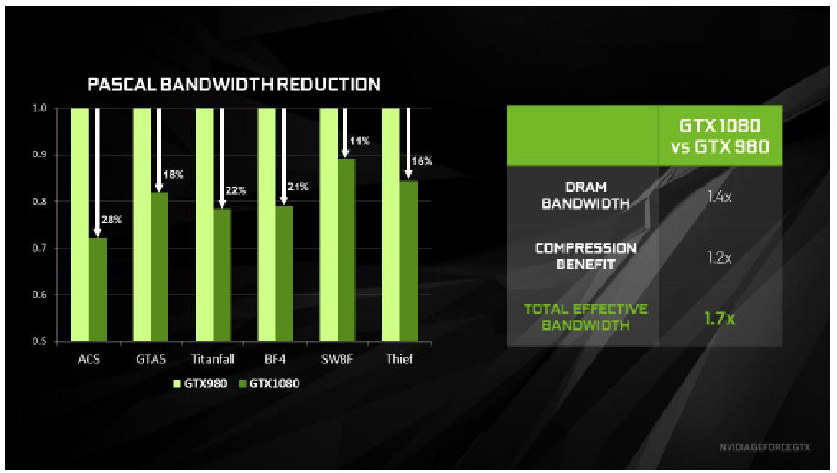
If you were paying attention on the first page of this review, you will see that the memory interface on the GTX 1080 is 256 bit. But the earlier GTX980 ti and GTX Titan X were both 384 bit. All of these cards use a system of enhanced memory compression, utilising lossless memory compression techniques to reduce DRAM bandwidth demands. Memory compression helps in three key areas; it:
- Reduces the amount of data written out to memory.
- Reduces the amount of data transferred from memory to L2 cache, effectively providing a capacity increase for the L2 cache, as a compressed tile (block of frame buffer pixels or samples) has a smaller memory footprint than an uncompressed tile.
- Reduces the amount of data transferred between clients such as the texture unit and the frame buffer.
Of all the algorithms the GPU compression pipeline has to handle, one of the most important is delta colour compression. The GPU will calculate the differences between pixels in a block and then store that block as a set of reference pixels as well as the delta values from the reference. If the deltas are small then only a few bits per pixel are required. If the packed result of reference values and the delta values is less than half the uncompressed storage size, then delta colour compression is successful and the data is stored at 2:1 compression, which is half size.

The GTX 1080 benefits from a significantly enhanced delta colour compression system.
- 2:1 compression has been improved to be more effective than before.
- A new 4:1 delta colour compression mode is added to cover cases where the per pixel deltas are very small and are possible to pack in 25% of the original storage.
- A new 8:1 delta colour compression mode is added to combine 4:1 constant colour compression of 2×2 pixel blocks with 2:1 compression of the deltas between those blocks.
The latest games place a dramatic workload on a graphics card, often running with multiple independent or asynchronous workloads that ultimately work together to create the final rendered image. For overlapping workloads, such as when a GPU is dealing with physics and audio processing Pascal has new ‘dynamic load balancing' support.
Maxwell architecture dealt with overlapping workloads with static partitioning of the GPU into a subset that runs graphics and a subset that runs compute. This was only efficient provided that the balance of work between the two loads was roughly matching the partitioning ratio. New hardware dynamic load balancing solves the problem by allowing either workflow to adapt to use idle resources.
Time critical workloads are another important asynchronous compute scenario. An asynchronous timewarp operation for instance must complete before scanout starts, or a frame is dropped. The GPU therefore in this scenario needs to support very fast, low latency preemption to move the less critical workload from the GPU, so the more critical workload can run as soon as possible.
A single rendering command from a game engine can possibly call for hundreds of draw calls, with each draw call asking for hundreds of triangles, with each triangle containing hundreds of pixels which each have to be shaded and rendered. Traditionally a GPU cycle that implements preemption at a high level in the graphics pipeline would have to complete all of this work before switching tasks, which could theoretically result in a very long delay.
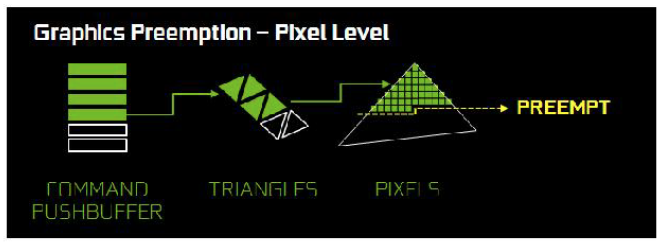
Nvidia wanted to improve this situation so they implemented Pixel Level Preemption in the GPU architecture of Pascal. The graphics units in Pascal are superior in that they can now keep track of their intermediate progress on rendering work, so when preemption is requested they can stop at that point, save off context information to start up later, and preempt quickly.

Fine work on the review, we are probably looking at £620 in the UK which is pretty steep
Too expensive
Can’t wait for the 1080 Ti to be released so I can upgrade my 980 Ti. Would love to have this 1080, but I think the price will be a bit too steep to validate a purchase at the moment. It does look like it will be a great upgrade for anyone else though, even with the 980 Ti it has quite a few games where it gets more than 10 fps extra on average.
It costs a small fortune, but holy crap that thing performs amazingly well. And with such little power consumption. Now the waiting begins, because it’ll take a few years before this kind of power becomes available to the less affluent consumers like me.
is that £619 for the founders edition? Because like many others I’m just going to go straight out for an aftermarket anyway so that gives a rough estimate on how they are going to be priced too (in the case that aftermarkets are based on the “normal” edition). Though it does offer more temptation to just wait for the Ti but I’ve done enough waiting by now xD
15% better than factory oced 980Ti for 700 euros isn’t a great jump in FPS/$ me thinks. 1080Ti or Vega are the ones for enthusiasts.
With these prices the to is looking £800+ probally more
Isn’t what usually happens is that by the time the Ti is released the 1080 will go down in price then Ti will cost the same amount as 1080’s release price?
What is the 980TI boosting too in this review? The G1 edition?
GTX980 to GTX1080Ti/Vega 11…come on, who will bring this HBM2 so I will play Star Citizen at 4K Ultra 60+ FPS?
Awesome card. Wish I could afford it. =x
Wait for custom cooled factory overclocked partner cards. They will be cheaper, faster and cooler.
Just a little off topic but will Fast sync have to be specifically supported by developer studios or can it just be enabled via the control panel (allowing for all games to make immediate use of it)?
AMD Radeon Pro Duo vs GTX 1080 vs GTX 1070 – Ultra performance test https://youtu.be/urYLez2aBew
So in overall, it is just a more efficient Maxwell with better granularity and less IPC per cluster, offset by higher clocks and a better software stack to make it up with the missing hardware scheduler, not impressed.
Does anyone know when EVGA will release their hybrid cooled GTX 1080s?
Think I’m going to wait to see what the Asus Strix 1080 OC (or whatever they’ll call it) can do. Happy with my 980 Strix until then 🙂
“This is the first time that Nvidia have introduced a vapour chamber cooling system on a reference card”
Uhm, the original NVTTM cooler used by the Titan, 780, and 780Ti used a vapor chamber. NVidia switched to the far worse heatpipe cooler for the Maxwell cards, which was the cause of their overheating problems.
I find the 1080 pretty underwhelming. It’s loud, it’s hot, it’s slower than a nearly two generation old 295X2 and barely faster than a 980Ti, it’s overpriced even compared to the faster AIB versions of itself, and since the entire NA market got a total of 36 cards for the launch, you can’t buy one anyways.
I am Brazilian , I need a gtx 970, but do not want to sell my motorcycle to buy , accept donation [email protected] my email
@4K+ the GTX 1080 is incredibly underwhelming, often only 8-9 FPS faster than a stock 980Ti.